
Even when these AI search instruments cited sources, they usually directed customers to syndicated variations of content material on platforms like Yahoo Information fairly than authentic writer websites. This occurred even in circumstances the place publishers had formal licensing agreements with AI corporations.
URL fabrication emerged as one other vital drawback. Greater than half of citations from Google’s Gemini and Grok 3 led customers to fabricated or damaged URLs leading to error pages. Of 200 citations examined from Grok 3, 154 resulted in damaged hyperlinks.
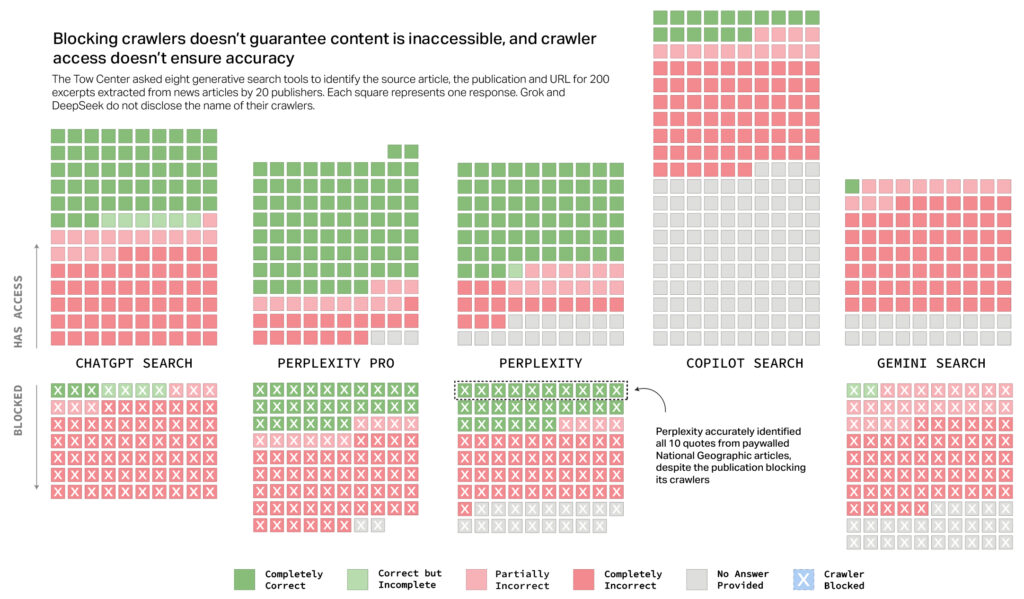
These points create vital pressure for publishers, which face tough decisions. Blocking AI crawlers may result in lack of attribution completely, whereas allowing them permits widespread reuse with out driving visitors again to publishers’ personal web sites.
Mark Howard, chief working officer at Time journal, expressed concern to CJR about guaranteeing transparency and management over how Time’s content material seems by way of AI-generated searches. Regardless of these points, Howard sees room for enchancment in future iterations, stating, “At present is the worst that the product will ever be,” citing substantial investments and engineering efforts geared toward bettering these instruments.
Nonetheless, Howard additionally did some consumer shaming, suggesting it is the consumer’s fault if they are not skeptical of free AI instruments’ accuracy: “If anyone as a shopper is correct now believing that any of those free merchandise are going to be 100% correct, then disgrace on them.”
OpenAI and Microsoft supplied statements to CJR acknowledging receipt of the findings however didn’t immediately handle the precise points. OpenAI famous its promise to assist publishers by driving visitors by way of summaries, quotes, clear hyperlinks, and attribution. Microsoft said it adheres to Robotic Exclusion Protocols and writer directives.
The most recent report builds on earlier findings revealed by the Tow Middle in November 2024, which recognized related accuracy issues in how ChatGPT dealt with news-related content material. For extra element on the pretty exhaustive report, take a look at Columbia Journalism Evaluate’s web site.


{kind=link}