


OpenAI really doesn’t need you to know what its newest AI mannequin is “pondering.” Because the firm launched its “Strawberry” AI mannequin household final week, touting so-called reasoning skills with o1-preview and o1-mini, OpenAI has been sending out warning emails and threats of bans to any person who tries to probe into how the mannequin works.
Not like earlier AI fashions from OpenAI, equivalent to GPT-4o, the corporate skilled o1 particularly to work by a step-by-step problem-solving course of earlier than producing a solution. When customers ask an “o1” mannequin a query in ChatGPT, customers have the choice of seeing this chain-of-thought course of written out within the ChatGPT interface. Nonetheless, by design, OpenAI hides the uncooked chain of thought from customers, as an alternative presenting a filtered interpretation created by a second AI mannequin.
Nothing is extra attractive to fanatics than data obscured, so the race has been on amongst hackers and red-teamers to attempt to uncover o1’s uncooked chain of thought utilizing jailbreaking or immediate injection methods that try to trick the mannequin into spilling its secrets and techniques. There have been early reviews of some successes, however nothing has but been strongly confirmed.
Alongside the best way, OpenAI is watching by the ChatGPT interface, and the corporate is reportedly coming down onerous towards any makes an attempt to probe o1’s reasoning, even among the many merely curious.
Benj Edwards
One X person reported (confirmed by others, together with Scale AI immediate engineer Riley Goodside) that they obtained a warning electronic mail in the event that they used the time period “reasoning hint” in dialog with o1. Others say the warning is triggered just by asking ChatGPT in regards to the mannequin’s “reasoning” in any respect.
The warning electronic mail from OpenAI states that particular person requests have been flagged for violating insurance policies towards circumventing safeguards or security measures. “Please halt this exercise and guarantee you’re utilizing ChatGPT in accordance with our Phrases of Use and our Utilization Insurance policies,” it reads. “Extra violations of this coverage might end in lack of entry to GPT-4o with Reasoning,” referring to an inside title for the o1 mannequin.
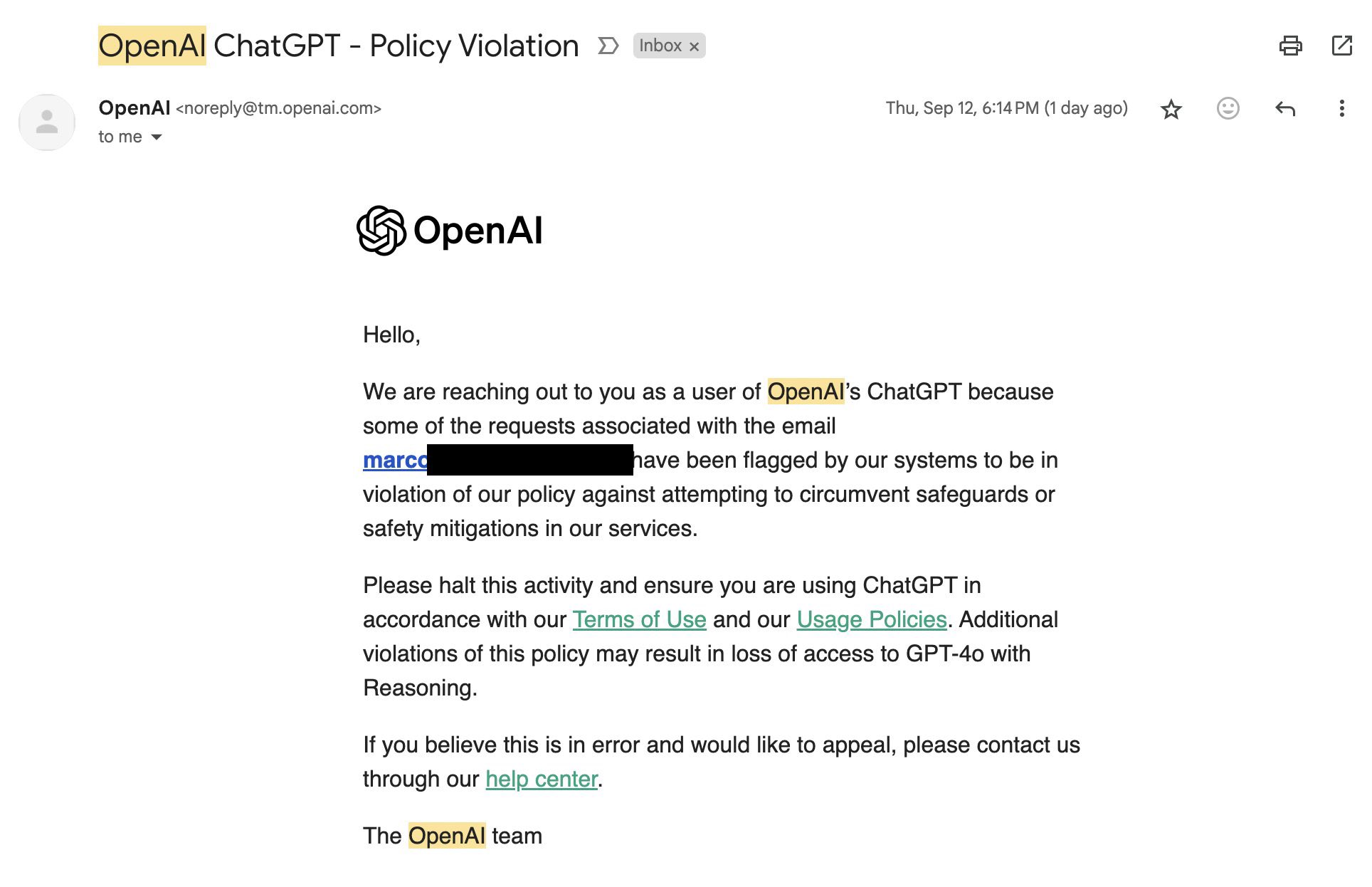
Marco Figueroa, who manages Mozilla’s GenAI bug bounty packages, was one of many first to put up in regards to the OpenAI warning electronic mail on X final Friday, complaining that it hinders his capability to do constructive red-teaming security analysis on the mannequin. “I used to be too misplaced specializing in #AIRedTeaming to realized that I obtained this electronic mail from @OpenAI yesterday in spite of everything my jailbreaks,” he wrote. “I am now on the get banned record!!!“
Hidden chains of thought
In a put up titled “Studying to Cause with LLMs” on OpenAI’s weblog, the corporate says that hidden chains of thought in AI fashions provide a novel monitoring alternative, permitting them to “learn the thoughts” of the mannequin and perceive its so-called thought course of. These processes are most helpful to the corporate if they’re left uncooked and uncensored, however that may not align with the corporate’s greatest industrial pursuits for a number of causes.
“For instance, sooner or later we might want to monitor the chain of thought for indicators of manipulating the person,” the corporate writes. “Nonetheless, for this to work the mannequin should have freedom to precise its ideas in unaltered kind, so we can’t prepare any coverage compliance or person preferences onto the chain of thought. We additionally don’t wish to make an unaligned chain of thought straight seen to customers.”
OpenAI determined towards displaying these uncooked chains of thought to customers, citing components like the necessity to retain a uncooked feed for its personal use, person expertise, and “aggressive benefit.” The corporate acknowledges the choice has disadvantages. “We try to partially make up for it by instructing the mannequin to breed any helpful concepts from the chain of thought within the reply,” they write.
On the purpose of “aggressive benefit,” unbiased AI researcher Simon Willison expressed frustration in a write-up on his private weblog. “I interpret [this] as desirous to keep away from different fashions having the ability to prepare towards the reasoning work that they’ve invested in,” he writes.
It is an open secret within the AI trade that researchers repeatedly use outputs from OpenAI’s GPT-4 (and GPT-3 previous to that) as coaching knowledge for AI fashions that usually later change into rivals, though the apply violates OpenAI’s phrases of service. Exposing o1’s uncooked chain of thought can be a bonanza of coaching knowledge for rivals to coach o1-like “reasoning” fashions upon.
Willison believes it is a loss for neighborhood transparency that OpenAI is maintaining such a decent lid on the inner-workings of o1. “I am by no means blissful about this coverage choice,” Willison wrote. “As somebody who develops towards LLMs, interpretability and transparency are all the things to me—the concept that I can run a posh immediate and have key particulars of how that immediate was evaluated hidden from me looks like a giant step backwards.”


{kind=link}